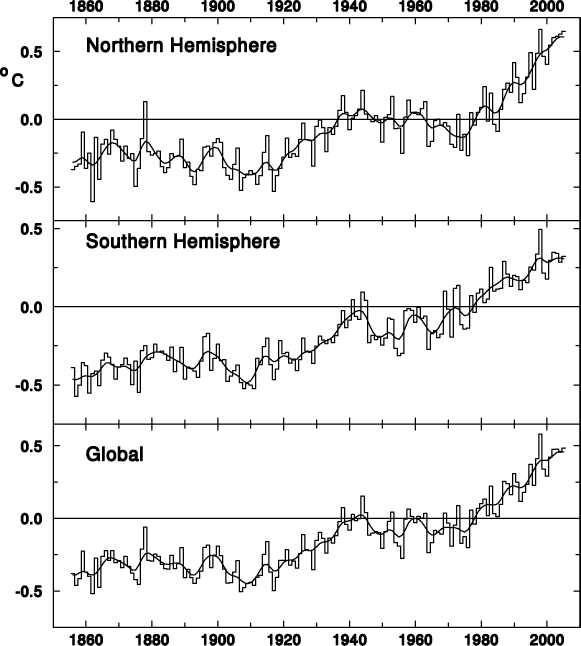
Hemispheric and global averages graph
(also available as a PostScript file)
These datasets have been superseded by later versions and are provided here as an archive. To obtain the current versions of these datasets, go to the CRU temperature data page.
|
Hemispheric and global averages graph (also available as a PostScript file) |
| Gridded data ASCII file format |
|---|
for year = startyear to endyear
for month = 1 to 12
for row = 1 to 36 (85-90N,80-85N,75-70N,...75-80S,80-85S,85-90S)
format(i4,i3,i2,72i6) year,month,field,180W-175W,175W-170W,...,175-180E
|
|
Missing values represented by -9999
Field=1: temperature anomalies wrt 1961-90 °C*100 (except "Absolute" which is mean temperature 1961-90 °C*100 although with only one decimal place of precision) Field=2: number of stations used at each grid box (only in CRUTEM2) |
| Hemispheric/global average data file format |
|---|
for year = 1856 to 2005 format(i5,13f7.3) year, 12 * monthly values, annual value format(i5,12i7) year, 12 * percentage coverage of hemisphere or globe |
NetCDF format
is read by many commercial data-processing packages
(eg. IDL)
and public-domain software
(eg. ncview, a NetCDF viewer,
and NCL, a scriptable data-manipulation and visualisation package)
Data for Downloading
ERRATUM: before 21st May 2003, the NetCDF versions erroneously used a time dimension
with units "months since (startyear)-1-1" that started from 1. It should (and now does) start from 0.
| Dataset | gzipped ASCII | zipped ASCII | NetCDF | gzipped NetCDF | Last updated |
|---|---|---|---|---|---|
| CRUTEM2 | crutem2.dat.gz 3.2mb |
crutem2.zip 3.2mb |
crutem2.nc 19.2mb |
crutem2.nc.gz 1.9mb |
2006-01-18 |
| CRUTEM2v | crutem2v.dat.gz 2.5mb |
crutem2v.zip 2.5mb |
crutem2v.nc 9.6mb |
crutem2v.nc.gz 1.8mb |
2006-01-18 |
| HadCRUT2 | hadcrut2.dat.gz 4.5mb |
hadcrut2.zip 4.5mb |
hadcrut2.nc 9.3mb |
hadcrut2.nc.gz 3.5mb |
2006-01-18 |
| HadCRUT2v | hadcrut2v.dat.gz 4.2mb |
hadcrut2v.zip 4.2mb |
hadcrut2v.nc 8.4mb |
hadcrut2v.nc.gz 3.3mb |
2006-01-18 |
| Absolute | absolute.dat.gz 47kb |
absolute.zip 47kb |
absolute.nc 63kb |
absolute.nc.gz 40kb |
1999-07-13 |
| Dataset | ASCII | Last updated | Description |
|---|---|---|---|
| TaveNH2v | tavenh2v.dat 28kb |
2006-01-18 | Northern Hemisphere average temp. 1856 to 2005 |
| TaveSH2v | tavesh2v.dat 28kb |
2006-01-18 | Southern Hemisphere average temp. 1856 to 2005 |
| TaveGL2v | tavegl2v.dat 28kb |
2006-01-18 | Global average temp. 1856 to 2005 |
What are the basic raw data used?
Over land regions of the world over 3000 monthly station temperature time series are used. Coverage is denser over the more populated parts of the world, particularly, the United States, southern Canada, Europe and Japan. Coverage is sparsest over the interior of the South American and African continents and over the Antarctic. The number of available stations was small during the 1850s, but increases to over 3000 stations during the 1951-90 period. For marine regions sea surface temperature (SST) measurements taken on board merchant and some naval vessels are used. As the majority come from the voluntary observing fleet, coverage is reduced away from the main shipping lanes and is minimal over the Southern Oceans. Maps/tables giving the density of coverage through time are given for land regions by Jones and Moberg (2003) and for the oceans by Rayner et al. (2003). Both these sources also extensively discuss the issue of consistency and homogeneity of the measurements through time and the steps that have made to ensure all non-climatic inhomogeneities have been removed.
Why are sea surface temperatures rather than air temperatures used over the oceans?
Over the ocean areas the most plentiful and most consistent measurements of temperature have been taken of the sea surface. Marine air temperatures (MAT) are also taken and would, ideally, be preferable when combining with land temperatures, but they involve more complex problems with homogeneity than SSTs (Rayner et al., 2003). The problems are reduced using night only marine air temperature (NMAT) but at the expense of discarding approximately half the MAT data. Our use of SST anomalies implies that we are tacitly assuming that the anomalies of SST are in agreement with those of MAT. Many tests show that NMAT anomalies agree well with SST anomalies on seasonal and longer time scales in most open ocean areas. Globally the agreement is currently very good (Rayner et al, 2003), even better than in Folland et al. (2001b). However, some regional discrepancies in open ocean trends have recently been found in the tropics (Christy et al., 2001).
Why are the temperatures expressed as anomalies from 1961-90?
Stations on land are at different elevations, and different countries estimate average monthly temperatures using different methods and formulae. To avoid biases that could result from these problems, monthly average temperatures are reduced to anomalies from the period with best coverage (1961-90). For stations to be used, an estimate of the base period average must be calculated. Because many stations do not have complete records for the 1961-90 period several methods have been developed to estimate 1961-90 averages from neighbouring records or using other sources of data. Over the oceans, where observations are generally made from mobile platforms, it is impossible to assemble long series of actual temperatures for fixed points. However it is possible to interpolate historical data to create spatially complete reference climatologies (averages for 1961-90) so that individual observations can be compared with a local normal for the given day of the year.
Why do anomalies not average exactly zero over 1961-90?
Over both the land and marine domains considerable care has been taken in calculating the base period values for the 1961-90 period. However, as all regions don't have complete data for this 30-year period, the anomaly data do not average exactly to zero for this 30-year period. This also applies to the global and hemispheric average series as well as the individual grid-box series. However, the IPCC optimally averaged global and hemispheric time series (see later web address) are constrained to have anomalies that average to zero over 1961-90.
How are the land and marine data combined?
Both the component parts (land and marine) are separately interpolated to the same 5ş x 5ş latitude/longitude grid boxes. The combined versions (HadCRUT2 and HadCRUT2v) take values from each component and weight the grid boxes where both occur (coastlines and islands). The weighting method is described in detail in Jones et al. (2001). Land temperature anomalies are infilled where more than four of the surrounding eight 5ş x 5ş grid boxes are present, as discussed in Jones et al. (2001). Infilling doesn't take place when the box is ocean, except when it covered by sea ice based on 1961-90 average conditions.
How accurate are the hemispheric and global averages?
Annual values are approximately accurate to +/- 0.05°C (two standard errors) for the period since 1951. They are about four times as uncertain during the 1850s, with the accuracy improving gradually between 1860 and 1950 except for temporary deteriorations during data-sparse, wartime intervals. Estimating accuracy is a far from a trivial task as the individual grid-boxes are not independent of each other and the accuracy of each grid-box time series varies through time (although the variance adjustment has reduced this influence to a large extent). The issue is discussed extensively by Folland et al. (2001a,b) and Jones et al. (1997). Both Folland et al. (2001a,b) references extend discussion to the estimate of accuracy of trends in the global and hemispheric series, including the additional uncertainties related to homogeneity corrections.
In the TaveNH/SH/GL2v files averages are now given to a precision of three decimal places to enable seasonal values to be calculated to ±0.01°C. The extra precision implies no greater accuracy than two decimal places.
Why do global and hemispheric temperature anomalies differ from those quoted in the IPCC assessment and the media?
We have areally averaged grid-box temperature anomalies (using the HadCRUT2v dataset), with weighting according to the area of each 5° x 5° grid box, into hemispheric values; we then averaged these two values to create the global-average anomaly. However, the global and hemispheric anomalies used by IPCC and in the World Meteorological Organization and Met Office news releases were calculated using optimal averaging. This technique uses information on how temperatures at each location co-vary, to weight the data to take best account of areas where there are no observations at a given time. The method uses the same basic information (i.e. in future HadCRUT2v and subsequent improvements), along with the data-coverage and the measurement and sampling errors, to estimate uncertainties on the global and hemispheric average anomalies. The more elementary technique (used here) produces no estimates of uncertainties, but our results generally lie within the ranges estimated by optimum averaging. The constraint that the average be zero over 1961-90 in the optimal averages also adds a small offset compared to the other data described here.
The present optimal averages with annual uncertainties are accessible from the Hadley Centre. The data include values filtered to show decadal and longer-term variations and uncertainties. This replaces the IPCC 2001 version at the above site (see Parker et al. 2004). All other versions of global and hemispheric temperature anomalies are only steps to the IPCC series.
Why are values slightly different when I download an updated file a year later?
All the files on this page (except Absolute) will be updated on a monthly basis to include the latest month within about four weeks of its completion. Updating includes not just data for the last month but the addition of any late reports for up to approximately the last two years. In addition to this the method of variance adjustment (used for CRUTEM2v and HadCRUT2v) works on the anomalous temperatures relative to the underlying trend on an approximate 30-year timescale. With the addition of subsequent years, the underlying trend will alter slightly, changing the variance-adjusted values. Effects will be greatest on the last year of the record, but an influence can be evident for the last three to four years. Full details of the variance adjustment procedure are given in Jones et al. (2001). Approximately yearly, the optimally averaged values will also be updated to take account of such additional past information.